À medida que as aplicações de IA e os Agentes de IA evoluem rapidamente, cada vez mais sistemas adotam arquiteturas de IA multimodelo. Os diferentes modelos de IA variam significativamente em capacidade de raciocínio, velocidade de resposta e estrutura de custos. Depender de um único modelo para todas as tarefas resulta frequentemente em custos excessivos ou ineficiência. Por esse motivo, o roteamento de modelos de IA tornou-se um componente essencial da infraestrutura moderna de IA.
Um Roteador de IA distribui de forma inteligente as tarefas entre vários modelos, conferindo aos sistemas de IA maior flexibilidade, escalabilidade e estabilidade. Esta abordagem multimodelo afirma-se como uma base técnica fundamental para plataformas SaaS de IA, Agentes de IA e aplicações automatizadas de IA.
O que é o roteamento de modelos de IA?
O roteamento de modelos de IA é um mecanismo técnico que seleciona o modelo mais adequado para cada pedido com base nos requisitos da tarefa.
Nas configurações tradicionais de IA, um sistema liga-se normalmente a apenas um modelo. Por exemplo, um chatbot pode chamar uma determinada API de modelo de linguagem de grande escala. No entanto, diferentes tarefas exigem capacidades distintas:
- Resumo de texto ou perguntas e respostas simples requer, em geral, um raciocínio mínimo
- Análise lógica complexa ou geração de código exige modelos mais potentes
- Tradução multilingue pode necessitar de um modelo especialmente otimizado
Utilizar um modelo de alto desempenho para todas as tarefas aumenta os custos, enquanto que um modelo mais simples a lidar com tarefas complexas pode comprometer a qualidade. O roteamento de modelos de IA analisa o conteúdo do pedido e atribui dinamicamente as tarefas ao modelo mais adequado, equilibrando desempenho e custos.
Por que razão as aplicações de IA precisam de vários modelos?
À medida que a tecnologia de IA avança, os modelos tornam-se cada vez mais especializados nas suas capacidades e casos de utilização. Este facto impulsiona a adoção de arquiteturas de IA multimodelo.
Em primeiro lugar, diferentes modelos destacam-se em áreas distintas. Alguns são mais fortes no raciocínio complexo, enquanto outros se distinguem pela velocidade ou eficiência de custos. Ao combinar modelos, o sistema pode escolher a melhor ferramenta para cada tarefa.
Em segundo lugar, uma arquitetura multimodelo reduz os custos operacionais. As tarefas simples utilizam modelos mais baratos, enquanto as complexas recorrem a modelos premium, reduzindo significativamente as despesas totais.
Em terceiro lugar, esta arquitetura melhora a fiabilidade. Se um modelo falhar ou ficar offline, o sistema pode encaminhar os pedidos para outro, garantindo um serviço ininterrupto.
Como funciona o roteamento de modelos de IA?
Os sistemas de roteamento de modelos de IA recorrem tipicamente a um Motor de Roteamento para decidir qual o modelo que processa um pedido. O motor considera vários fatores:
Complexidade da tarefa: O sistema analisa a extensão do prompt e o tipo de tarefa para avaliar a potência do modelo necessária.
Capacidade do modelo: Diferentes modelos de IA têm desempenhos distintos em tarefas específicas, como geração de código ou processamento multimodal.
Velocidade de resposta: Para aplicações em tempo real, como chatbots e Agentes de IA, a baixa latência é crucial.
Custo da chamada: Os preços dos API de modelos de IA variam muito, pelo que o custo influencia as decisões de roteamento.
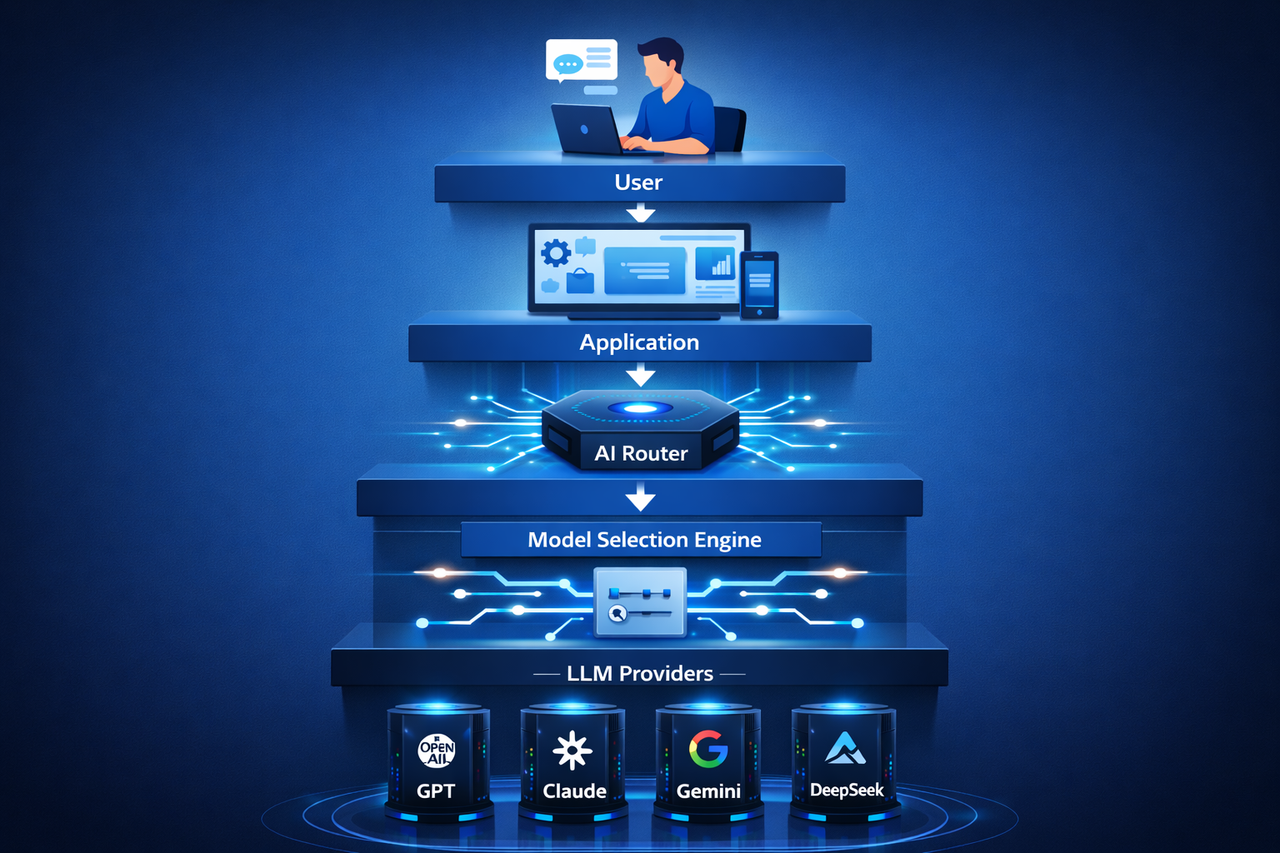
Quando um utilizador ou Agente de IA envia um pedido, o Roteador de IA analisa primeiro a tarefa, seleciona o modelo ideal, processa o pedido e devolve o resultado à aplicação.
Comparação das principais estratégias de roteamento de IA
Na infraestrutura real de IA, o roteamento de modelos emprega várias estratégias para otimizar o desempenho.
Estratégia focada no custo: Prioriza modelos mais baratos, mudando apenas para modelos de alto desempenho em tarefas complexas.
Estratégia focada no desempenho: Privilegia a qualidade do resultado, utilizando normalmente o modelo mais capaz, mesmo a um custo mais elevado.
Estratégia híbrida: Muitos Roteadores de IA modernos adotam uma abordagem híbrida, equilibrando custo, desempenho e velocidade de resposta.
Estratégia específica para tarefas: Seleciona modelos especialmente otimizados para determinadas tarefas, como geração de código ou processamento multimodal.
Diferentes estratégias adequam-se a diferentes aplicações, pelo que os sistemas de roteamento são normalmente ajustados a necessidades específicas.
Roteamento de modelos de IA vs. Gateway de API de IA
O roteamento de modelos de IA e o Gateway de API tradicional servem propósitos distintos.
Gateway de API de IA: Gere pedidos de API, lidando com autenticação, controlo de tráfego e segurança, mas não decide qual o modelo de IA a utilizar.
Roteador de Modelos de IA: Seleciona o melhor modelo de IA com base no conteúdo do pedido e encaminha em conformidade.
Na prática, os programadores combinam frequentemente ambos: o Gateway de API gere os pedidos, enquanto o Roteador de IA trata da seleção do modelo.
Casos de uso típicos do roteamento de modelos de IA
À medida que o ecossistema de IA cresce, o roteamento de modelos é amplamente aplicado em cenários onde vários modelos colaboram para obter eficiência.
Agentes de IA: Frequentemente chamam diferentes modelos para tarefas como pesquisa, análise e geração de conteúdo. O roteamento de modelos ajuda-os a escolher automaticamente o melhor modelo.
Plataformas SaaS de IA: Muitas oferecem múltiplos LLM aos utilizadores. Um Roteador de IA gere centralmente estas APIs de modelo.
Análise de dados de IA: Diferentes modelos tratam, respetivamente, da análise de dados, do raciocínio lógico e da geração de resultados.
Arquitetura típica de uma infraestrutura de Roteador de IA
Um sistema de Roteador de IA completo inclui várias camadas:
Camada de acesso à API: Recebe pedidos de aplicações ou Agentes de IA.
Camada de decisão de roteamento: Analisa o conteúdo do pedido para decidir qual o modelo de IA a utilizar.
Camada de execução do modelo: Liga-se a vários fornecedores de modelos, por exemplo, a diversos serviços LLM.
Sistema de monitorização e otimização: Acompanha o desempenho do modelo, os tempos de resposta e os custos, melhorando continuamente as estratégias de roteamento.
Esta arquitetura permite que o Roteador de IA distribua eficientemente as tarefas entre modelos, construindo uma infraestrutura de IA mais flexível.
O papel do Gate.AI no espaço do Roteador de IA
À medida que as aplicações de IA multimodelo crescem, surgiram plataformas especializadas de Roteador de IA para ajudar os programadores a gerir múltiplos modelos.
Algumas infraestruturas de IA oferecem agora interfaces de acesso a modelos unificados, como a plataforma de roteamento de modelos de IA Gate.AI, concebida para gerir múltiplos serviços LLM.
Ao contrário dos gateways de API de IA tradicionais, o Gate.AI foca-se em casos de uso de IA automatizados. Fornece acesso a modelos para Agentes de IA, suportando chamadas automatizadas e execução de tarefas. Integra também o protocolo x402 para pagamento automático de API de Agentes de IA, permitindo que as máquinas paguem por serviços de forma integrada.
Resumo
O roteamento de modelos de IA é uma tecnologia chave na arquitetura de IA multimodelo. Ao distribuir dinamicamente tarefas entre modelos, o Roteador de IA ajuda as aplicações a equilibrar desempenho, custo e velocidade.
Com o aumento dos Agentes de IA e das aplicações automatizadas, a arquitetura multimodelo está a tornar-se uma grande tendência. O roteamento de modelos de IA não só aumenta a eficiência, como também melhora a estabilidade e a flexibilidade.
Neste panorama, as plataformas de Roteador de IA estão a tornar-se infraestruturas vitais que conectam modelos de IA, programadores e aplicações automatizadas.
Perguntas frequentes
O que é o roteamento de modelos de IA?
O roteamento de modelos de IA é um mecanismo técnico que seleciona dinamicamente o melhor modelo de entre vários modelos de IA para lidar com um determinado pedido.
Qual é a diferença entre Roteador de IA e Roteador de LLM?
Um Roteador de LLM é especificamente concebido para modelos de linguagem de grande escala, enquanto um Roteador de IA abrange uma gama mais ampla de tipos de modelos de IA.
Por que razão as aplicações de IA precisam de uma arquitetura multimodelo?
Diferentes modelos diferem em capacidade, custo e velocidade. Uma arquitetura multimodelo permite que o sistema escolha o melhor modelo para cada tarefa.
Como é que o roteamento de modelos de IA reduz os custos?
Ao encaminhar tarefas simples para modelos de baixo custo e tarefas complexas para modelos de alto desempenho, o sistema reduz as despesas operacionais totais.








