AI Request Routing é uma capacidade de infraestrutura desenvolvida para gerenciar recursos de inferência de múltiplos modelos. Com a evolução contínua de grandes modelos de linguagem como GPT, Claude, Gemini e DeepSeek, cada vez mais aplicações de IA integram diversos modelos simultaneamente. A escolha inteligente entre diferentes modelos tornou-se um tema essencial na arquitetura de sistemas de IA.
O Gate.AI atua como intermediário entre aplicações e serviços de modelo, funcionando como um Gateway de IA e uma camada de roteamento de modelos. À medida que arquiteturas multi-modelo se consolidam como padrão do setor, o roteamento de modelos impacta não apenas o desempenho do sistema, mas também o controle de custos, a estabilidade do serviço e as capacidades autônomas dos Agentes de IA.
O que é roteamento de solicitações de IA?
Trata-se de um mecanismo de agendamento que seleciona automaticamente um modelo-alvo com base nas características da tarefa. Em arquiteturas tradicionais, o roteamento de solicitações de IA geralmente envolve uma aplicação que chama um único modelo fixo para concluir tarefas de inferência. Já em uma arquitetura multi-modelo, diferentes modelos oferecem vantagens distintas, como capacidade de raciocínio, geração de código, processamento de textos longos ou eficiência de custos.
A camada de roteamento analisa o conteúdo da solicitação e a encaminha ao modelo mais adequado para execução, otimizando assim o uso geral dos recursos.
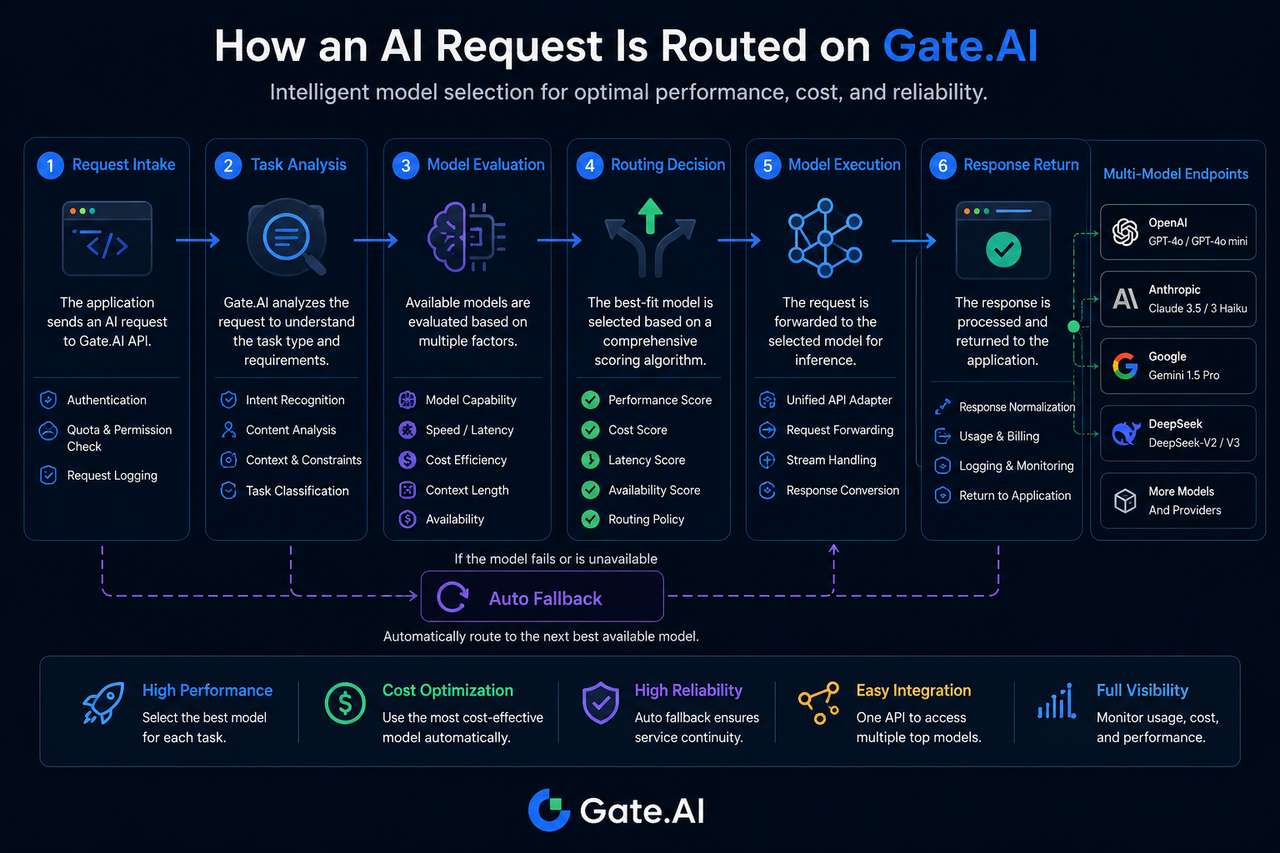
Etapa 1: A solicitação de IA entra no Gate.AI
O processo de roteamento começa com a fase de acesso da solicitação.
Quando uma aplicação envia uma solicitação, ela primeiro chega à camada de Gateway do Gate.AI. Nesse momento, o sistema verifica as informações de identidade, confere as permissões de acesso e registra os parâmetros da solicitação.
O conteúdo da solicitação geralmente inclui:
- Entrada do usuário
- Configuração do modelo
- Limites de token
- Requisitos de formato de resposta
- Estratégia de invocação
Após a verificação, a solicitação segue para a próxima fase de análise.
Etapa 2: O sistema analisa o tipo de tarefa
A identificação da tarefa é um componente essencial do roteamento de modelos.
O Gate.AI determina o tipo de tarefa com base nas características da solicitação, por exemplo:
- Conversa geral
- Resumo de textos longos
- Criação de conteúdo
- Geração de código
- Análise de dados
- Chamadas de ferramentas de agente
Tarefas distintas exigem capacidades de modelo muito diferentes.
Uma identificação precisa da tarefa torna o processo de correspondência de modelo mais eficiente.
Etapa 3: Avaliação e correspondência da capacidade do modelo
A fase de avaliação do modelo define o conjunto de modelos candidatos.
O sistema consulta o banco de dados de capacidades do modelo para filtrar os modelos disponíveis no momento.
As dimensões de avaliação normalmente incluem:
- Capacidade de raciocínio
- Comprimento do contexto
- Velocidade de resposta
- Capacidade de chamada de ferramentas
- Suporte multimodal
- Nível de custo
Por exemplo, tarefas complexas de raciocínio podem priorizar modelos com maior capacidade analítica, enquanto o processamento de documentos longos favorece modelos que suportam janelas de contexto ultra longas.
Etapa 4: Gerar a decisão de roteamento
A fase de decisão de roteamento define o modelo final de execução.
Após a identificação dos modelos candidatos, o sistema os pontua combinando várias métricas.
Os fatores de referência comuns incluem:
Desempenho do modelo
O desempenho do modelo determina a qualidade da conclusão da tarefa.
Problemas complexos geralmente exigem raciocínio lógico mais robusto, enquanto tarefas simples podem não precisar do modelo de maior desempenho.
Latência de resposta
A velocidade de resposta impacta diretamente a experiência do usuário.
Em cenários de interação em tempo real, modelos de baixa latência geralmente recebem prioridade mais alta.
Custo de invocação
Os custos de inferência variam entre diferentes modelos.
Quando múltiplos modelos conseguem concluir a mesma tarefa, o sistema pode priorizar aquele com maior eficiência de recursos.
Disponibilidade do serviço
O status do modelo também é um fator importante nas decisões de roteamento.
Se um modelo estiver com limite de taxa, apresentando falhas ou congestionado, o sistema reduz automaticamente sua prioridade.
Etapa 5: Solicitação enviada ao modelo-alvo
Após a decisão de roteamento, a solicitação é encaminhada ao modelo-alvo.
Nessa fase, o Gate.AI lida de forma unificada com as diferenças de interface entre os diversos provedores de modelos.
Os desenvolvedores de aplicação não precisam criar interfaces separadas para cada modelo.
Uma camada de acesso unificada reduz a complexidade do desenvolvimento e melhora a escalabilidade do sistema.
Etapa 6: Modelo gera resultado e retorna
Após o modelo-alvo concluir a inferência, o resultado é retornado ao Gate.AI.
O Gate.AI padroniza a resposta, garantindo estruturas de dados consistentes vindas de diferentes modelos.
Um formato de saída unificado reduz o trabalho de adaptação na camada de aplicação e simplifica a integração subsequente do sistema.
O resultado final é retornado à aplicação ou ao Agente de IA.
O que acontece quando o modelo-alvo está indisponível?
A indisponibilidade de modelo é algo comum em um ecossistema multi-modelo.
Se o modelo-alvo expirar, atingir o limite de taxa ou apresentar anomalias de serviço, o Gate.AI pode acionar um processo automático de fallback.
O sistema re-seleciona um modelo de backup de acordo com políticas predefinidas para continuar executando a tarefa.
Esse mecanismo reduz o risco de pontos únicos de falha e melhora a continuidade geral do serviço.
Para mais detalhes sobre esse processo, consulte "O que Acontece Quando um Modelo de IA Falha? Uma Análise Completa do Fluxo do Mecanismo Automático de Fallback do Gate.AI."
Exemplo de um processo de roteamento de solicitações de IA
O exemplo a seguir mostra um fluxo típico para uma tarefa de geração de conteúdo:
| Fase |
Ação do Sistema |
| Acesso da solicitação |
Aplicação envia solicitação de geração |
| Análise da tarefa |
Identificada como criação de conteúdo de texto longo |
| Filtragem de modelos |
Selecionar modelos candidatos que suportam contexto longo |
| Decisão de roteamento |
Pontuar com base em desempenho, custo e latência |
| Execução do modelo |
Solicitação enviada ao modelo-alvo |
| Processamento do resultado |
Retornar saída padronizada |
| Recuperação de falha |
Alternar automaticamente para modelo de backup, se necessário |
Esse processo geralmente é concluído em um tempo muito curto, e os usuários muitas vezes não percebem a seleção do modelo ocorrendo nos bastidores.
Resumo
Como capacidade central do Gateway de IA, o roteamento de solicitações de IA seleciona dinamicamente o modelo mais adequado para executar uma tarefa entre vários grandes modelos de linguagem. Em comparação com a invocação fixa de um único modelo, o roteamento de modelos aproveita ao máximo os pontos fortes de diferentes modelos, aumentando a flexibilidade, a estabilidade e a utilização de recursos do sistema.
Na arquitetura do Gate.AI, uma solicitação de IA passa por vários estágios: acesso da solicitação, identificação da tarefa, avaliação do modelo, decisão de roteamento, execução do modelo e retorno do resultado.
Perguntas Frequentes
Por que o Gate.AI precisa de roteamento de modelo?
O Gate.AI conecta diversos ecossistemas de modelos de IA, onde diferentes modelos se destacam em raciocínio, geração de código, processamento de texto longo e outras áreas. O roteamento de modelo seleciona automaticamente o mais adequado com base nos requisitos da tarefa.
Uma única solicitação de IA pode chamar vários modelos ao mesmo tempo?
Normalmente, uma única solicitação de IA é executada por um modelo-alvo. No entanto, em cenários mais complexos, pode-se utilizar um padrão de colaboração multi-modelo, onde diferentes modelos lidam com partes distintas da tarefa.
Quais fatores são considerados principalmente nas decisões de roteamento de IA?
As decisões de roteamento de IA geralmente consideram múltiplos fatores, como desempenho do modelo, velocidade de resposta, custo de inferência, comprimento do contexto, capacidade de chamada de ferramentas e disponibilidade do serviço.
Qual é a diferença entre roteamento de modelo e balanceamento de carga?
O balanceamento de carga lida principalmente com a distribuição de tráfego, enquanto o roteamento de modelo foca na correspondência de capacidade do modelo. O roteamento de modelo seleciona o modelo mais adequado com base nas características da tarefa, e não simplesmente distribui o tráfego de solicitações.








