AI Request Routing adalah kemampuan infrastruktur yang dirancang untuk mengelola sumber daya inferensi multi-model. Seiring dengan perkembangan model bahasa besar seperti GPT, Claude, Gemini, dan DeepSeek, semakin banyak aplikasi AI yang mengintegrasikan beberapa model secara bersamaan. Cara cerdas memilih di antara model-model yang berbeda telah menjadi topik krusial dalam desain sistem AI.
Gate.AI berada di antara aplikasi dan layanan model, berfungsi sebagai Gerbang AI dan lapisan perutean model. Dengan arsitektur multi-model yang menjadi standar industri, perutean model tidak hanya memengaruhi kinerja sistem, tetapi juga pengendalian biaya, stabilitas layanan, dan kemampuan otonom Agen AI.
Apa Itu AI Request Routing?
Sebagai mekanisme penjadwalan yang secara otomatis memilih model target berdasarkan karakteristik tugas, AI request routing dalam arsitektur tradisional biasanya melibatkan aplikasi yang memanggil satu model tetap untuk menyelesaikan tugas inferensi. Dalam arsitektur multi-model, setiap model menawarkan keunggulan berbeda, seperti kemampuan penalaran, pembuatan kode, pemrosesan teks panjang, atau efisiensi biaya.
Lapisan perutean model menganalisis konten permintaan dan mengirimkannya ke model yang paling sesuai untuk dieksekusi, sehingga meningkatkan pemanfaatan sumber daya secara keseluruhan.
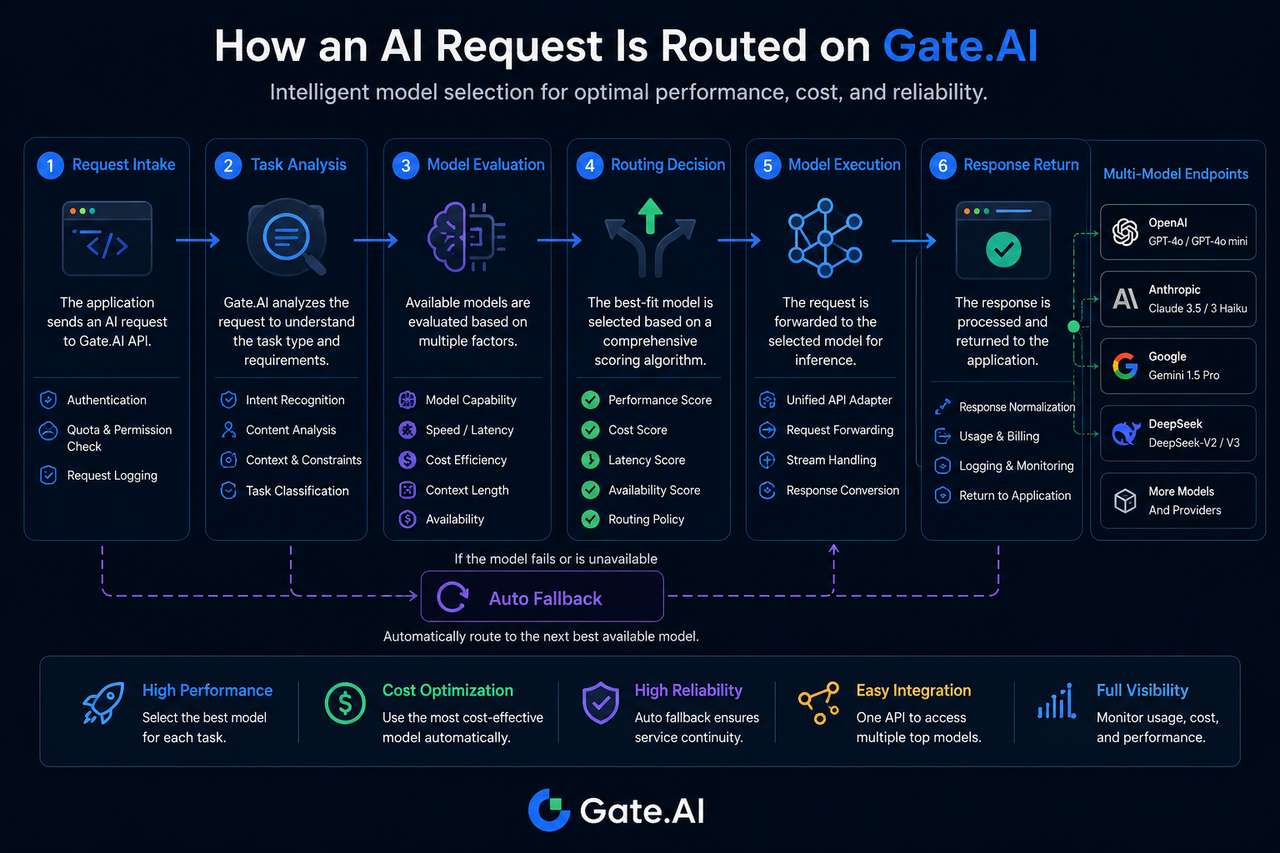
Langkah 1: Permintaan AI Masuk ke Gate.AI
Proses perutean dimulai dengan fase akses permintaan.
Ketika aplikasi mengirimkan permintaan, permintaan tersebut pertama-tama masuk ke lapisan Gerbang Gate.AI. Pada titik ini, sistem memverifikasi informasi identitas, memeriksa izin akses, dan mencatat parameter permintaan.
Konten permintaan biasanya mencakup:
- Input pengguna
- Konfigurasi model
- Batas token
- Persyaratan format respons
- Strategi pemanggilan
Setelah verifikasi, permintaan dilanjutkan ke fase analisis berikutnya.
Langkah 2: Sistem Menganalisis Jenis Tugas
Identifikasi tugas adalah komponen kunci perutean model.
Gate.AI menentukan jenis tugas berdasarkan karakteristik permintaan, misalnya:
- Percakapan umum
- Ringkasan teks panjang
- Pembuatan konten
- Pembuatan kode
- Analisis data
- Panggilan alat agen
Setiap tugas memiliki persyaratan kemampuan model yang sangat berbeda.
Identifikasi tugas yang akurat membuat proses pencocokan model selanjutnya lebih efisien.
Langkah 3: Evaluasi dan Pencocokan Kemampuan Model
Fase evaluasi model menentukan kisaran model kandidat.
Sistem merujuk basis data kemampuan model untuk memfilter model yang saat ini tersedia.
Dimensi evaluasi biasanya mencakup:
- Kemampuan penalaran
- Panjang konteks
- Kecepatan respons
- Kemampuan pemanggilan alat
- Dukungan multimodal
- Tingkat biaya
Misalnya, tugas penalaran kompleks mungkin memprioritaskan model dengan kemampuan penalaran lebih kuat, sementara tugas pemrosesan dokumen panjang lebih cocok untuk model yang mendukung jendela konteks ultra-panjang.
Langkah 4: Hasilkan Keputusan Perutean
Fase keputusan perutean menentukan model eksekusi akhir.
Setelah model kandidat diidentifikasi, sistem memberi skor dengan menggabungkan beberapa metrik.
Faktor referensi yang umum meliputi:
Kinerja Model
Kinerja model menentukan kualitas penyelesaian tugas.
Masalah kompleks biasanya membutuhkan penalaran logis yang lebih kuat, sementara tugas sederhana mungkin tidak memerlukan model dengan kinerja tertinggi.
Latensi Respons
Kecepatan respons secara langsung berdampak pada pengalaman pengguna.
Untuk skenario interaksi real-time, model dengan latensi rendah sering kali mendapat prioritas lebih tinggi.
Biaya Pemanggilan
Biaya inferensi bervariasi di setiap model.
Ketika beberapa model dapat menyelesaikan tugas yang sama, sistem dapat memprioritaskan model dengan efisiensi sumber daya lebih tinggi.
Ketersediaan Layanan
Status model juga merupakan faktor penting dalam keputusan perutean.
Jika sebuah model dibatasi laju, mengalami kegagalan, atau padat, sistem secara otomatis menurunkan prioritasnya.
Langkah 5: Permintaan Dikirim ke Model Target
Setelah keputusan perutean dibuat, permintaan diteruskan ke model target.
Pada tahap ini, Gate.AI menangani perbedaan antarmuka di berbagai penyedia model secara seragam.
Pengembang aplikasi tidak perlu mengembangkan antarmuka terpisah untuk model yang berbeda.
Lapisan akses terpadu mengurangi kompleksitas pengembangan dan meningkatkan skalabilitas sistem.
Langkah 6: Model Menghasilkan Hasil dan Mengembalikannya
Setelah model target menyelesaikan inferensi, hasilnya dikembalikan ke Gate.AI.
Gate.AI menstandarisasi respons, memastikan struktur data yang konsisten dari model yang berbeda.
Format output yang terpadu mengurangi pekerjaan adaptasi lapisan aplikasi dan menyederhanakan integrasi sistem selanjutnya.
Hasil akhir dikembalikan ke aplikasi atau Agen AI.
Apa yang Terjadi Ketika Model Target Tidak Tersedia?
Ketidaktersediaan model adalah kejadian umum dalam ekosistem multi-model.
Jika model target mengalami waktu habis, dibatasi laju, atau mengalami anomali layanan, Gate.AI dapat memicu proses fallback otomatis.
Sistem memilih ulang model cadangan sesuai dengan kebijakan yang telah ditetapkan untuk terus menjalankan tugas.
Mekanisme ini mengurangi risiko titik kegagalan tunggal dan meningkatkan kesinambungan layanan secara keseluruhan.
Untuk informasi lebih lanjut tentang proses ini, lihat "Apa yang Terjadi Ketika Model AI Gagal? Analisis Alur Lengkap Mekanisme Fallback Otomatis Gate.AI."
Contoh Proses AI Request Routing
Contoh berikut menunjukkan alur tipikal untuk tugas pembuatan konten:
| Fase |
Tindakan Sistem |
| Akses permintaan |
Aplikasi mengirimkan permintaan pembuatan |
| Analisis tugas |
Diidentifikasi sebagai pembuatan konten teks panjang |
| Pemfilteran model |
Pilih model kandidat yang mendukung konteks panjang |
| Keputusan perutean |
Skor berdasarkan kinerja, biaya, dan latensi |
| Eksekusi model |
Permintaan dikirim ke model target |
| Pemrosesan hasil |
Mengembalikan output yang terstandarisasi |
| Pemulihan kegagalan |
Secara otomatis beralih ke model cadangan jika perlu |
Proses ini biasanya selesai dalam waktu yang sangat singkat, dan pengguna sering kali tidak merasakan pemilihan model yang terjadi di belakang layar.
Ringkasan
Sebagai kemampuan inti dari Gerbang AI, AI request routing secara dinamis memilih model yang paling sesuai untuk menjalankan tugas di antara beberapa model bahasa besar. Dibandingkan dengan pemanggilan model tunggal tetap, perutean model memanfaatkan sepenuhnya kekuatan model yang berbeda, meningkatkan fleksibilitas, stabilitas, dan pemanfaatan sumber daya sistem.
Dalam arsitektur Gate.AI, permintaan AI melewati beberapa tahap: akses permintaan, identifikasi tugas, evaluasi model, keputusan perutean, eksekusi model, dan pengembalian hasil.
FAQ
Mengapa Gate.AI Membutuhkan Perutean Model?
Gate.AI menghubungkan beberapa ekosistem model AI, di mana setiap model unggul dalam penalaran, pembuatan kode, pemrosesan teks panjang, dan area lainnya. Perutean model secara otomatis memilih model yang paling sesuai berdasarkan persyaratan tugas.
Dapatkah Satu Permintaan AI Memanggil Beberapa Model Secara Bersamaan?
Biasanya, satu permintaan AI dieksekusi oleh satu model target. Namun, dalam beberapa skenario kompleks, pola kolaborasi multi-model dapat digunakan, di mana model yang berbeda menangani bagian tugas yang berbeda.
Faktor Apa yang Terutama Dipertimbangkan dalam Keputusan Perutean AI?
Keputusan perutean AI biasanya mempertimbangkan beberapa faktor seperti kinerja model, kecepatan respons, biaya inferensi, panjang konteks, kemampuan pemanggilan alat, dan ketersediaan layanan.
Apa Perbedaan Antara Perutean Model dan Load Balancing?
Load balancing terutama menangani distribusi lalu lintas, sementara perutean model berfokus pada pencocokan kemampuan model. Perutean model memilih model yang paling sesuai berdasarkan karakteristik tugas, bukan sekadar mendistribusikan lalu lintas permintaan.








