À mesure que les applications d’IA et les agents IA évoluent rapidement, de plus en plus de systèmes adoptent des architectures multimodèles. Les modèles d’IA diffèrent sensiblement en matière de capacité de raisonnement, de vitesse de réponse et de structure de coûts. S’appuyer sur un seul modèle pour toutes les tâches entraîne souvent des coûts excessifs ou un manque d’efficacité. C’est pourquoi le routage de modèles d’IA est devenu un élément crucial de l’infrastructure moderne de l’IA.
Un routeur d’IA répartit intelligemment les tâches entre plusieurs modèles, offrant aux systèmes d’IA une plus grande flexibilité, évolutivité et stabilité. Cette approche multimodèle s’impose comme un fondement technique essentiel pour les plateformes SaaS d’IA, les agents IA et les applications d’IA automatisées.
Qu’est-ce que le routage de modèles d’IA ?
Le routage de modèles d’IA est un mécanisme technique qui sélectionne le modèle le plus adapté à chaque requête en fonction des besoins de la tâche.
Dans les configurations d’IA traditionnelles, un système se connecte généralement à un seul modèle. Par exemple, un chatbot peut appeler une API de grand modèle de langage. Or, différentes tâches exigent des capacités distinctes :
- Le résumé de texte ou les questions-réponses simples nécessitent généralement un raisonnement minimal.
- L’analyse logique complexe ou la génération de code requièrent des modèles plus puissants.
- La traduction multilingue peut bénéficier d’un modèle spécialement optimisé.
Utiliser un modèle haute performance pour chaque tâche alourdit les coûts, tandis qu’un modèle plus simple traitant des tâches complexes risque de dégrader la qualité. Le routage de modèles d’IA analyse le contenu des requêtes et attribue dynamiquement les tâches au modèle le plus pertinent, trouvant ainsi un équilibre entre performance et coût.
Pourquoi les applications d’IA ont-elles besoin de plusieurs modèles ?
À mesure que la technologie de l’IA progresse, les modèles deviennent de plus en plus spécialisés dans leurs capacités et leurs cas d’usage. Cela favorise l’adoption d’architectures d’IA multimodèles.
D’abord, différents modèles excellent dans des domaines variés. Certains sont plus performants en raisonnement complexe, tandis que d’autres se distinguent par leur rapidité ou leur rentabilité. En combinant les modèles, le système peut choisir l’outil le mieux adapté à chaque tâche.
Ensuite, une architecture multimodèle réduit les coûts d’exploitation. Les tâches simples utilisent des modèles peu coûteux, tandis que les tâches complexes font appel à des modèles premium – ce qui réduit considérablement les dépenses totales.
Enfin, cette architecture améliore la fiabilité. Si un modèle tombe en panne ou devient indisponible, le système peut rediriger les requêtes vers un autre, garantissant un service ininterrompu.
Les systèmes de routage de modèles d’IA reposent généralement sur un moteur de routage pour décider quel modèle traite une requête. Le moteur prend en compte plusieurs facteurs :
Complexité de la tâche : le système analyse la longueur de l’invite et le type de tâche pour évaluer la puissance nécessaire.
Capacité du modèle : différents modèles d’IA performent différemment sur des tâches spécifiques, comme la génération de code ou le traitement multimodal.
Vitesse de réponse : pour les applications temps réel comme les chatbots et les agents IA, une faible latence est cruciale.
Coût d’appel : les prix des API des modèles d’IA varient considérablement, ce qui influence les décisions de routage.
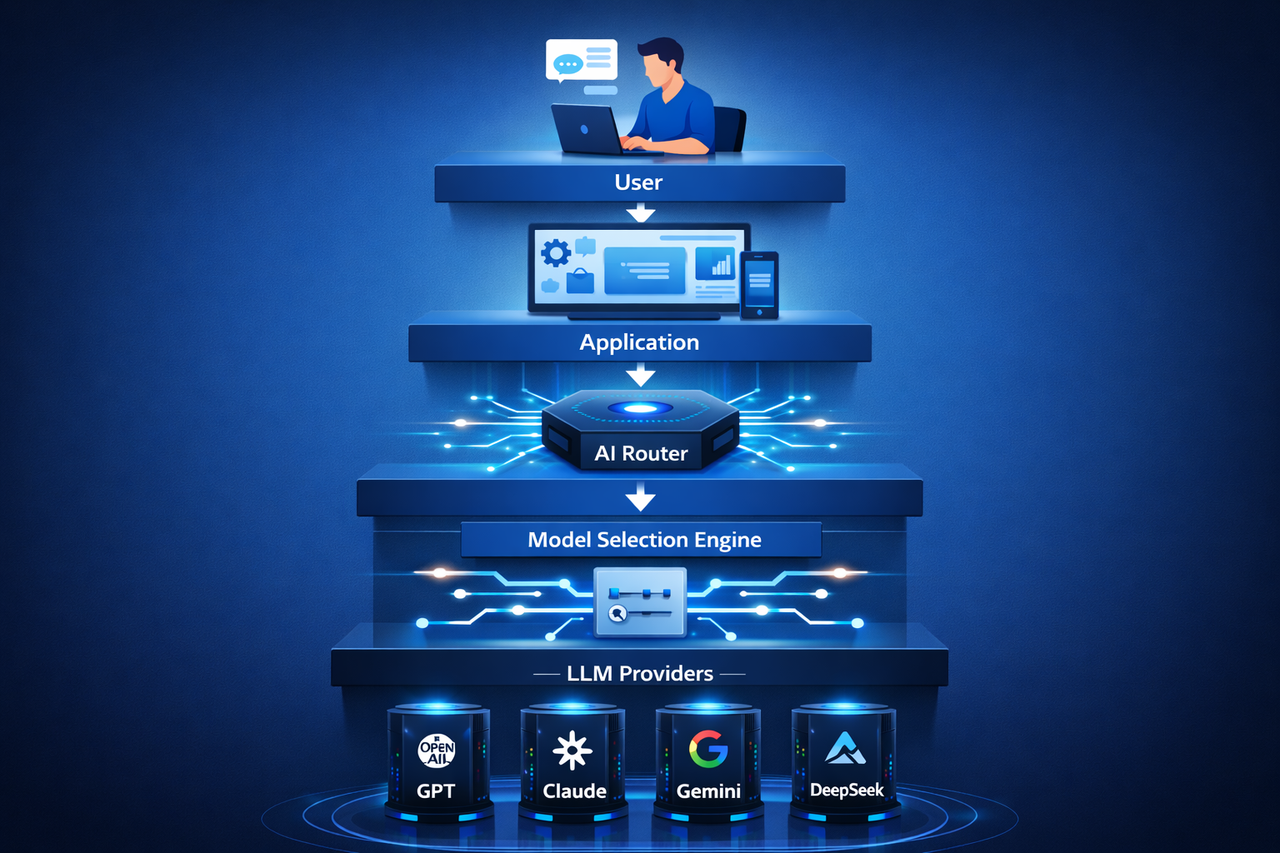
Lorsqu’un utilisateur ou un agent IA envoie une requête, le routeur d’IA analyse d’abord la tâche, sélectionne le modèle optimal, traite la requête et renvoie le résultat à l’application.
Comparaison des principales stratégies de routage d’IA
Dans l’infrastructure IA concrète, le routage de modèles emploie plusieurs stratégies pour optimiser les performances.
Stratégie axée sur les coûts : privilégie les modèles les moins chers, ne passant aux modèles haute performance que pour les tâches complexes.
Stratégie axée sur la performance : mise sur la qualité des résultats, utilisant généralement le modèle le plus performant, même à un coût plus élevé.
Stratégie hybride : de nombreux routeurs d’IA modernes adoptent une approche hybride, équilibrant coût, performance et vitesse de réponse.
Stratégie spécifique à la tâche : sélectionne des modèles spécialement optimisés pour certaines tâches, comme la génération de code ou le traitement multimodal.
Chaque stratégie convient à des applications différentes, c’est pourquoi les systèmes de routage sont généralement adaptés à des besoins spécifiques.
Routage de modèles d’IA vs passerelle API d’IA
Le routage de modèles d’IA et la passerelle API traditionnelle remplissent des fonctions distinctes.
Passerelle API d’IA : gère les requêtes API – authentification, contrôle de trafic, sécurité – mais ne décide pas quel modèle d’IA utiliser.
Routeur de modèles d’IA : sélectionne le meilleur modèle d’IA en fonction du contenu de la requête et achemine la requête en conséquence.
En pratique, les développeurs combinent souvent les deux : la passerelle API gère les requêtes, tandis que le routeur d’IA gère la sélection du modèle.
Cas d’usage typiques du routage de modèles d’IA
Avec la croissance de l’écosystème IA, le routage de modèles est largement appliqué dans les scénarios où plusieurs modèles collaborent pour gagner en efficacité.
Agents IA : ils appellent souvent différents modèles pour des tâches comme la recherche, l’analyse et la génération de contenu. Le routage de modèles les aide à choisir automatiquement le meilleur modèle.
Plateformes SaaS d’IA : beaucoup proposent plusieurs LLM à leurs utilisateurs. Un routeur d’IA gère ces API de modèles de manière centralisée.
Analyse de données IA : différents modèles traitent respectivement l’analyse des données, le raisonnement logique et la génération de résultats.
Architecture typique d’une infrastructure de routeur d’IA
Un système complet de routeur d’IA comprend plusieurs couches :
Couche d’accès API : reçoit les requêtes des applications ou des agents IA.
Couche de décision de routage : analyse le contenu de la requête pour décider quel modèle d’IA utiliser.
Couche d’exécution des modèles : se connecte à plusieurs fournisseurs de modèles, par exemple divers services LLM.
Système de supervision et d’optimisation : suit les performances des modèles, les temps de réponse et les coûts, améliorant en continu les stratégies de routage.
Cette architecture permet au routeur d’IA de répartir efficacement les tâches entre les modèles, construisant une infrastructure IA plus flexible.
Le rôle de Gate.AI dans l’univers des routeurs d’IA
Avec l’essor des applications d’IA multimodèles, des plateformes spécialisées de routeurs d’IA ont vu le jour pour aider les développeurs à gérer plusieurs modèles.
Certaines infrastructures d’IA proposent désormais des interfaces d’accès unifiées aux modèles, comme la plateforme de routage de modèles d’IA Gate.AI, conçue pour gérer plusieurs services LLM.
Contrairement aux passerelles API d’IA traditionnelles, Gate.AI se concentre sur les cas d’usage d’IA automatisés. Elle offre un accès aux modèles pour les agents IA, prenant en charge les appels automatisés et l’exécution de tâches. Elle intègre également le protocole x402 pour le paiement automatique des API des agents IA, permettant aux machines d’effectuer des paiements de manière transparente.
Résumé
Le routage de modèles d’IA est une technologie clé dans l’architecture d’IA multimodèle. En répartissant dynamiquement les tâches entre les modèles, le routeur d’IA aide les applications à équilibrer performance, coût et rapidité.
Avec la montée en puissance des agents IA et des applications automatisées, l’architecture multimodèle devient une tendance majeure. Le routage de modèles d’IA améliore non seulement l’efficacité, mais aussi la stabilité et la flexibilité.
Dans ce contexte, les plateformes de routeurs d’IA s’affirment comme une infrastructure essentielle reliant les modèles d’IA, les développeurs et les applications automatisées.
FAQ
Qu’est-ce que le routage de modèles d’IA ?
Le routage de modèles d’IA est un mécanisme technique qui sélectionne dynamiquement le meilleur modèle parmi plusieurs modèles d’IA pour traiter une requête donnée.
Quelle est la différence entre un routeur d’IA et un routeur LLM ?
Un routeur LLM est spécifiquement conçu pour les grands modèles de langage, tandis qu’un routeur d’IA couvre une gamme plus large de types de modèles d’IA.
Pourquoi les applications d’IA ont-elles besoin d’une architecture multimodèle ?
Les modèles diffèrent en capacités, coût et rapidité. Une architecture multimodèle permet au système de choisir le meilleur modèle pour chaque tâche.
Comment le routage de modèles d’IA réduit-il les coûts ?
En orientant les tâches simples vers des modèles peu coûteux et les tâches complexes vers des modèles haute performance, le système réduit les dépenses d’exploitation globales.








