Con la rápida evolución de las aplicaciones de IA y los agentes de IA, cada vez más sistemas adoptan arquitecturas multimodelo. Los distintos modelos de IA difieren notablemente en capacidad de razonamiento, velocidad de respuesta y estructura de costes. Depender de un único modelo para todas las tareas suele traducirse en costes excesivos o ineficiencia. Por eso, el enrutamiento de modelos de IA se ha convertido en un componente esencial de la infraestructura moderna de IA.
Un enrutador de IA asigna tareas de forma inteligente entre varios modelos, dotando a los sistemas de IA de mayor flexibilidad, escalabilidad y estabilidad. Este enfoque multimodelo se perfila como una base técnica clave para plataformas SaaS de IA, agentes de IA y aplicaciones automatizadas de IA.
¿Qué es el enrutamiento de modelos de IA?
El enrutamiento de modelos de IA es un mecanismo técnico que selecciona el modelo más adecuado para cada solicitud en función de los requisitos de la tarea.
En las configuraciones tradicionales de IA, un sistema suele conectarse a un solo modelo. Por ejemplo, un chatbot podría llamar a una API de un modelo de lenguaje de gran tamaño. Sin embargo, distintas tareas exigen capacidades diferentes:
- El resumen de texto o las preguntas y respuestas sencillas generalmente requieren un razonamiento mínimo.
- El análisis lógico complejo o la generación de código demandan modelos más potentes.
- La traducción multilingüe puede necesitar un modelo especialmente optimizado.
Emplear un modelo de alto rendimiento para cada tarea incrementa los costes, mientras que un modelo más simple que aborde tareas complejas puede comprometer la calidad. El enrutamiento de modelos de IA analiza el contenido de la solicitud y asigna dinámicamente las tareas al modelo más idóneo, logrando un equilibrio entre rendimiento y coste.
¿Por qué las aplicaciones de IA necesitan múltiples modelos?
A medida que la tecnología de IA avanza, los modelos se especializan cada vez más en sus capacidades y casos de uso. Esto impulsa la adopción de arquitecturas de IA multimodelo.
En primer lugar, diferentes modelos destacan en áreas distintas. Algunos son más sólidos en razonamiento complejo, mientras que otros sobresalen por su velocidad o eficiencia de costes. Al combinar modelos, el sistema puede elegir la herramienta óptima para cada tarea.
En segundo lugar, una arquitectura multimodelo reduce los costes operativos. Las tareas simples utilizan modelos más baratos, mientras que las complejas recurren a modelos premium, lo que reduce significativamente los gastos totales.
En tercer lugar, esta arquitectura mejora la fiabilidad. Si un modelo falla o se desconecta, el sistema puede redirigir las solicitudes a otro, garantizando un servicio ininterrumpido.
¿Cómo funciona el enrutamiento de modelos de IA?
Los sistemas de enrutamiento de modelos de IA suelen basarse en un motor de enrutamiento para decidir qué modelo procesa una solicitud. El motor considera varios factores:
Complejidad de la tarea: El sistema analiza la longitud de la instrucción y el tipo de tarea para evaluar la potencia del modelo necesaria.
Capacidad del modelo: Diferentes modelos de IA rinden de forma distinta en tareas específicas, como la generación de código o el procesamiento multimodal.
Velocidad de respuesta: Para aplicaciones en tiempo real como chatbots y agentes de IA, la baja latencia es crucial.
Coste de la llamada: Los precios de las API de modelos de IA varían ampliamente, por lo que el coste influye en las decisiones de enrutamiento.
Cuando un usuario o un agente de IA envía una solicitud, el enrutador de IA primero analiza la tarea, selecciona el modelo óptimo, procesa la solicitud y devuelve el resultado a la aplicación.
Comparación de estrategias principales de enrutamiento de IA
En la infraestructura de IA real, el enrutamiento de modelos emplea varias estrategias para optimizar el rendimiento.
Estrategia de prioridad de coste: Prioriza modelos más baratos, cambiando solo a modelos de alto rendimiento para tareas complejas.
Estrategia de prioridad de rendimiento: Se centra en la calidad de salida, utilizando normalmente el modelo más potente incluso a mayor coste.
Estrategia híbrida: Muchos enrutadores de IA modernos utilizan un enfoque híbrido, equilibrando coste, rendimiento y velocidad de respuesta.
Estrategia específica de tarea: Selecciona modelos especialmente optimizados para ciertas tareas, como la generación de código o el procesamiento multimodal.
Diferentes estrategias se adaptan a distintas aplicaciones, por lo que los sistemas de enrutamiento suelen ajustarse a necesidades concretas.
Enrutamiento de modelos de IA frente a pasarela de API de IA
El enrutamiento de modelos de IA y la pasarela de API tradicional tienen propósitos distintos.
Pasarela de API de IA: Gestiona las solicitudes de API —autenticación, control de tráfico y seguridad—, pero no decide qué modelo de IA usar.
Enrutador de modelos de IA: Selecciona el mejor modelo de IA según el contenido de la solicitud y lo enruta en consecuencia.
En la práctica, los desarrolladores suelen combinar ambas: la pasarela de API gestiona las solicitudes, mientras que el enrutador de IA se encarga de la selección del modelo.
Casos de uso típicos del enrutamiento de modelos de IA
A medida que el ecosistema de IA crece, el enrutamiento de modelos se aplica ampliamente en escenarios donde múltiples modelos colaboran para lograr eficiencia.
Agentes de IA: A menudo llaman a diferentes modelos para tareas como búsqueda, análisis y generación de contenido. El enrutamiento de modelos les ayuda a elegir automáticamente el modelo óptimo.
Plataformas SaaS de IA: Muchas ofrecen múltiples LLM a los usuarios. Un enrutador de IA gestiona centralmente estas API de modelos.
Análisis de datos con IA: Diferentes modelos se encargan del análisis de datos, el razonamiento lógico y la generación de resultados respectivamente.
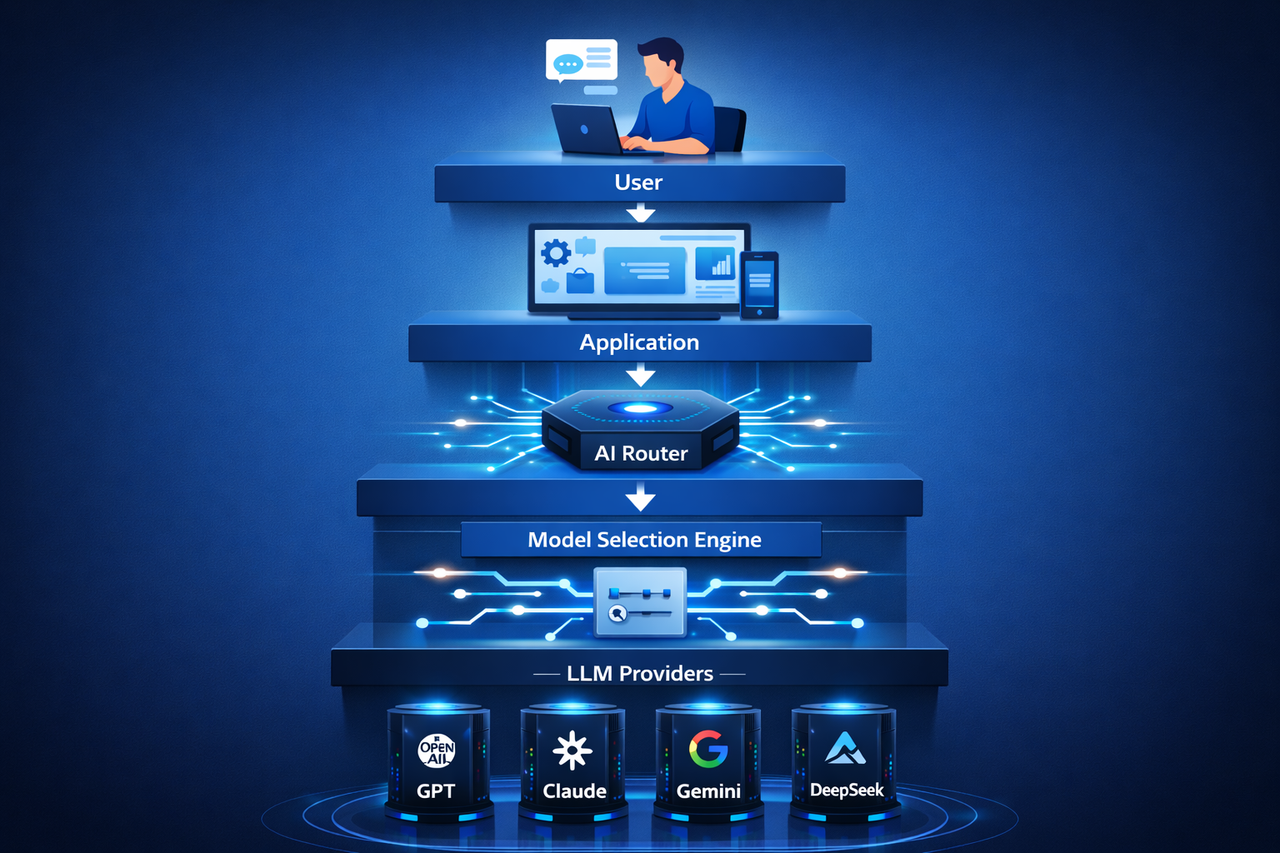
Arquitectura típica de una infraestructura de enrutador de IA
Un sistema completo de enrutador de IA incluye varias capas:
Capa de acceso a la API: Recibe solicitudes de aplicaciones o agentes de IA.
Capa de decisión de enrutamiento: Analiza el contenido de la solicitud para decidir qué modelo de IA utilizar.
Capa de ejecución de modelos: Se conecta a múltiples proveedores de modelos, por ejemplo, varios servicios de LLM.
Sistema de supervisión y optimización: Realiza un seguimiento del rendimiento del modelo, los tiempos de respuesta y los costes, mejorando continuamente las estrategias de enrutamiento.
Esta arquitectura permite al enrutador de IA distribuir tareas de manera eficiente entre los modelos, construyendo una infraestructura de IA más flexible.
El papel de Gate.AI en el espacio del enrutador de IA
A medida que crecen las aplicaciones de IA multimodelo, han surgido plataformas especializadas de enrutadores de IA para ayudar a los desarrolladores a gestionar múltiples modelos.
Algunas infraestructuras de IA ofrecen ahora interfaces de acceso a modelos unificadas, como la plataforma de enrutamiento de modelos de IA Gate.AI, diseñada para gestionar múltiples servicios de LLM.
A diferencia de las pasarelas de API de IA tradicionales, Gate.AI se centra en casos de uso automatizados de IA. Proporciona acceso a modelos para agentes de IA, soportando llamadas automatizadas y ejecución de tareas. También integra el protocolo x402 para el pago automático de API de agentes de IA, permitiendo que las máquinas paguen por servicios sin problemas.
Resumen
El enrutamiento de modelos de IA es una tecnología clave en la arquitectura de IA multimodelo. Al distribuir dinámicamente las tareas entre modelos, el enrutador de IA ayuda a las aplicaciones a equilibrar rendimiento, coste y velocidad.
Con el auge de los agentes de IA y las aplicaciones automatizadas, la arquitectura multimodelo se está convirtiendo en una tendencia importante. El enrutamiento de modelos de IA no solo mejora la eficiencia, sino que también aumenta la estabilidad y la flexibilidad.
En este panorama, las plataformas de enrutadores de IA se están convirtiendo en una infraestructura vital que conecta modelos de IA, desarrolladores y aplicaciones automatizadas.
Preguntas frecuentes
¿Qué es el enrutamiento de modelos de IA?
El enrutamiento de modelos de IA es un mecanismo técnico que selecciona dinámicamente el mejor modelo entre varios modelos de IA para manejar una solicitud determinada.
¿Cuál es la diferencia entre enrutador de IA y enrutador de LLM?
Un enrutador de LLM está diseñado específicamente para modelos de lenguaje de gran tamaño, mientras que un enrutador de IA abarca una gama más amplia de tipos de modelos de IA.
¿Por qué las aplicaciones de IA necesitan una arquitectura multimodelo?
Diferentes modelos difieren en capacidad, coste y velocidad. Una arquitectura multimodelo permite que el sistema elija el mejor modelo para cada tarea.
¿Cómo reduce el enrutamiento de modelos de IA los costes?
Al enrutar tareas simples a modelos de bajo coste y tareas complejas a modelos de alto rendimiento, el sistema reduce los gastos operativos generales.









